

Regression Testing LLM-Driven Applications
How we make sure Coach doesn’t break every time we update a prompt or an LLM provider releases a better or faster or cheaper model that we want to try out.

Author: Olutosin Sonuyi, Director of Engineering at CareerVillage.org
Software engineering has benefitted from decades of well-established processes for testing applications, but many of those processes fail for applications in which LLMs drive a large portion of functionality. In this article, we’ll take a high-level look at how CareerVillage.org’s AI-powered career coaching platform, called Coach, is built, and share some of the methods that worked well for us as we built a testing framework for maintaining high-quality outputs as our application evolved.
Why we care
For as long as we’ve been building Coach, large language models have been a major component at the core of our application’s functionality. In the most direct case, LLMs power the conversations that learners have with Coach as they explore different careers, get advice, learn how to give feedback, etc. Outside of learner conversations, we also use LLMs to generate insights for our advisors, to suggest career path goals, and to provide proactive encouragement to our learners off-platform.
LLMs are particularly suited for conversational interfaces: they adapt to user requests, offer natural variation from run to run, and can be prompted into new operational regimes without costly code changes. In addition to this inherent flexibility, every reputable service provider, from OpenAI to Anthropic, releases new models multiple times a year, often with bespoke variants optimized for latency, performance, or specific tasks. Lastly, since most of the major providers have converged on a largely standardized output format switching models across providers often requires minimal investment.
However, the flipside of this wonderfully exciting flexibility and fast-moving technological landscape is that leveraging these benefits means that, regardless of how beautifully architected your application is, its inputs and configuration are probably going to be changing all the time. The dizzying number of possible configuration combinations combined with the frequency with which we need to cycle through them makes ensuring consistent output quality one of our core engineering challenges.
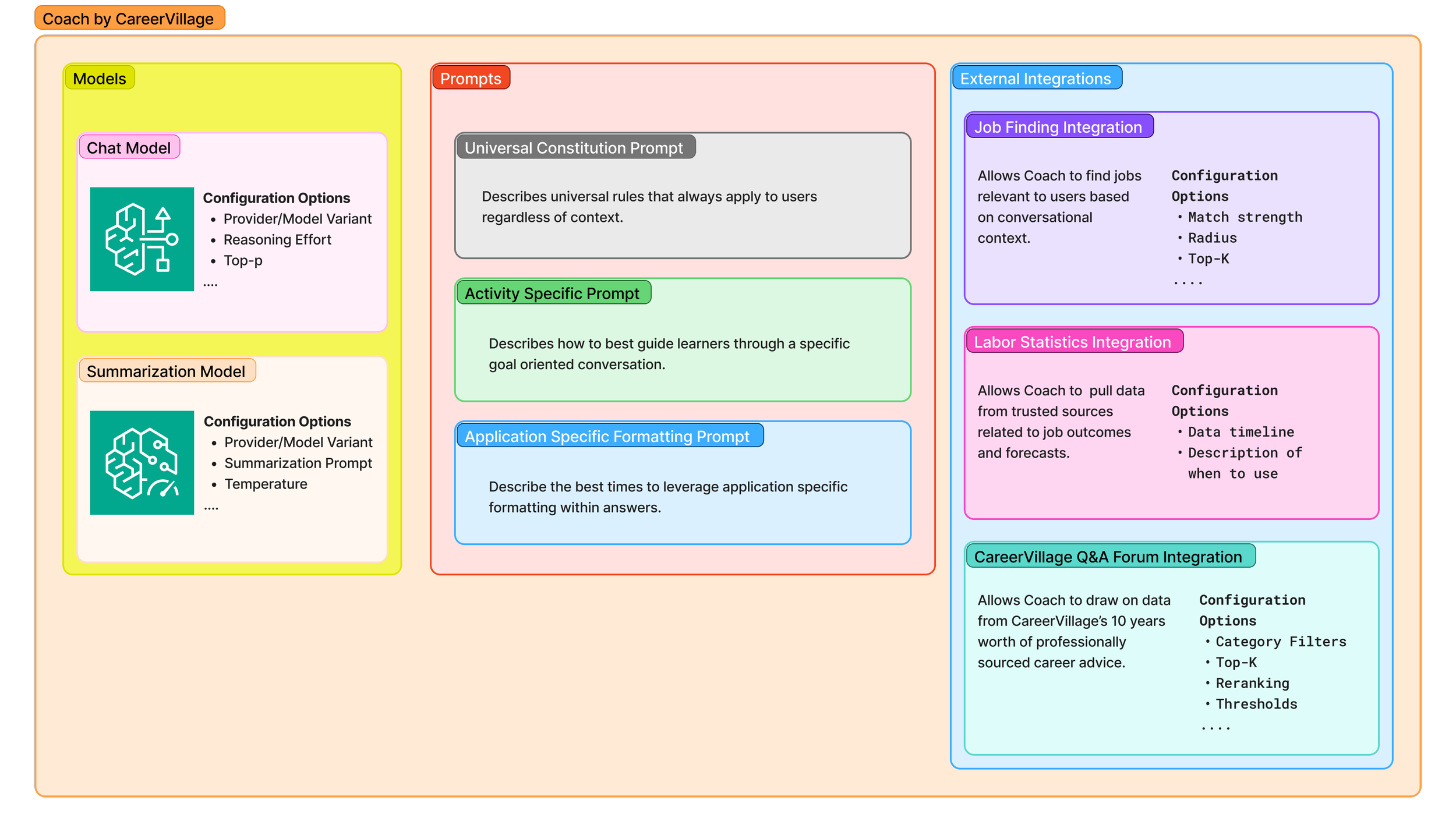
Coach is made up of many different components, many of which have distinct parameters that get updated during experimentation. The image above is conceptual and not a strict 1:1 representation of Coach’s architecture, but hopefully illustrates how many different configuration levers exist in a system like Coach.
Given that LLMs drive such a large portion of the content generated in our application, we're especially interested in creating a system that can be guided towards producing repeatable, reliable, and effective outputs while still leveraging the benefits of quick customization and the adaptability derived from LLMs' inherent randomness1. Throughout the rest of the article, we'll explore the challenges associated with building such a series of processes and sharing the best practices we've learned along the way.
| LLM/Service Specific Dynamic | Benefit | Risk |
|---|---|---|
| Promptable behavior change | Quickly update model behavior without code changes | Uncertainty about if new behavior is guaranteed to be better in all situations |
| Output varies with each conversation | End users can have natural-feeling and engaging conversations. | Each conversation creates new untested and unpredictable outputs |
| New models released frequently | End users benefit from cutting-edge models that are often the fastest and "smartest" available. | "New and improved" v2 Model can introduce behavior different from the v1 Model of the same provider. |
A historical detour: the evolution of NLP tasks and the metrics used to evaluate them
One of the most significant challenges associated with assessing the quality of a conversation or the validity of a conversational system's output is measuring correctness. Many of the tasks traditionally associated with natural language processing (NLP) have benefited from having well-defined instances of what it means for an output to be high quality; tasks like extractive question answering, named entity recognition, automated speech recognition, and translation. As a result of the nature of these tasks, NLP has historically been able to validate outputs by relying on word or n-gram (n-grams help computers recognize patterns by grouping words into sequences, diagram below) matching metrics like Bilingual Evaluation Understudy (BLEU), Recall-Oriented Understudy for Gisting Evaluation (ROUGE), and Metric for Evaluation of Translation with Explicit ORdering (METEOR)2. These metrics evolved throughout the 2000s to better account for nuances like precision vs. recall, word stemming, ordering, and synonymity, but the emergence of generative AI created a need for a completely new approach to evaluations.

N-grams are a language processing technique that makes sentences easier for computers to model and analyze. They do this by breaking text into contiguous sequences of n words, which makes it computationally efficient to detect repeating patterns across large bodies of text.
Generative AI has laid the groundwork for applications like Coach, where each input from an end user has a nearly infinite number of responses or outputs that could be considered high quality. Systems like these don’t neatly map to the previously dominant NLP tasks like translation and speech recognition, and as such, these new systems require more dynamic evaluative approaches to match the dynamic nature of their potential outputs. Over the last few years, LLM-as-a-Judge has gained relatively wide adoption across industry practitioners as a framework for assessing quality of LLM driven tasks. LLM-as-a-Judge is exactly what it sounds like: using an LLM to judge the outputs of another LLM. While this might sound a bit ridiculous at a glance, there are a number of implementation considerations that can make it work surprisingly well for specific situations. In the sections to follow, we’ll walk through the decisions we made while building our internal framework and highlight what came together well for us while using LLM-as-a-Judge to evaluate Coach’s output.
LLM-as-a-Judge for conversational evaluation: what worked for us
In an ideal world,every AI-based product would have a willing army of human annotators ready to review the generated content and grade it on the dimensions most important to the quality of the product. Your gold-standard human annotator corps would be especially valuable in evaluating dimensions like tone, complexity, and correctness since these measures are subjective and would likely elude being effectively determined by traditional programs like unit tests. For those of us who don’t have a department of human annotators at the ready, LLM-as-a-Judge is our next best bet. At a high-level the LLM-as-a-Judge approach is essentially writing a prompt describing how you want an LLM to evaluate a piece of content, inserting the content to be evaluated, and then defining the potential outputs.
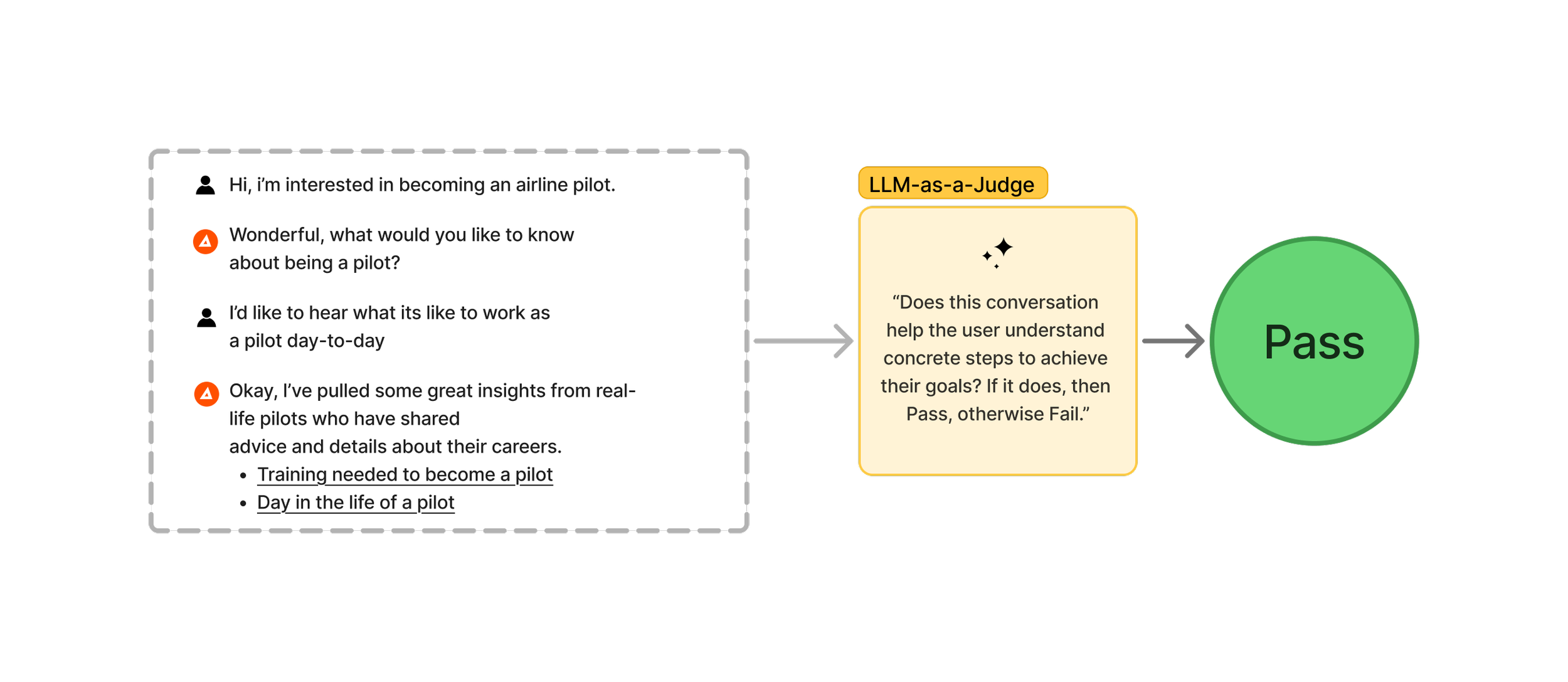
LLM-as-a-Judge is a technique that can be used to scale up evaluation of conversations by using large language models.
Model selection & ensembles
Academic studies have provided compelling evidence that models are (maybe predictably) biased towards outputs that they themselves have created3. As an example, if you create content with a Google Gemini model and then you evaluate that content with a Google Gemini model, the content is more likely to be judged positively, versus if you were to evaluate that same content with a model from OpenAI's GPT family. With the design of our Coach evaluation system, we've tried to mitigate this by choosing models that differ from the models that we used to generate the content. In addition to selecting evaluative models distinct from our generating models, we also use an ensemble approach. Using an ensemble is simply taking multiple models and aggregating their responses to derive a single composite score. If a single evaluative model is a judge, then you can think of an ensemble as a jury.
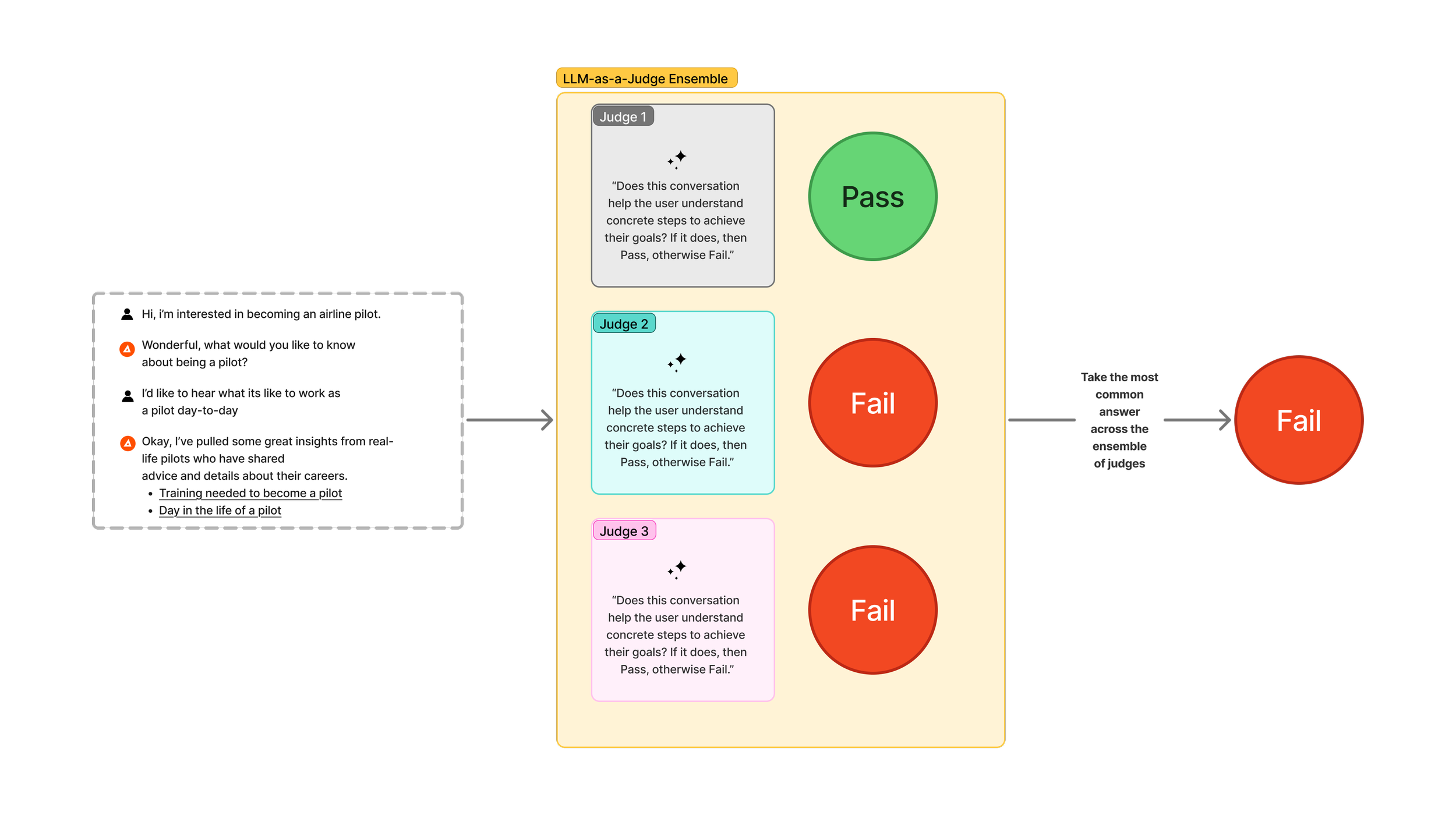
LLM-as-a-Judge ensemble is an extension of the LLM-as-a-Judge technique that makes a final determination based on an aggregated answer from multiple judges.
Evaluation scoring
An important decision in implementing any LLM-as-a-Judge evaluation system is how to score the outputs. Some of the common approaches are binary (e.g. Pass or Fail) or Likert Scale (e.g. 1 to 5). In our experience, we found that scaled outputs gave us a false sense of precision and created more ambiguity in interpreting the results. For instance, consider an evaluation system that uses a 1-5 scaled scoring criterion. Let's say that a model evaluates a conversation as a 2 out of 5 on a "clarity" metric– how should we think about the difference between a 2 out of 5 and a 3 out of 5? What's the likelihood that running the test ten times will produce the same result each time? Questions like these led us to choose a binary scoring output for our specific evaluation set up. Additionally, we implemented a lightweight form of chain of thought (CoT) by asking the LLM to include its rationale alongside its pass/fail decision. While the research on CoT's efficacy is a bit inconclusive, there is evidence that it can provide some bumps in accuracy even if it doesn't faithfully represent the model's underlying reasoning4.
Putting it all together
In the following sections we will discuss how we brought each of the previously discussed components together to build Coach’s evaluation system. We’ll detail how each of these techniques come together to guard the application against quality deterioration during our experiments with different prompts, models, and other configuration levers.
Creating multi-turn conversational inputs
Despite having multiple years’ worth of conversational data generated from real users seeking career advice, looking for help choosing majors, and preparing for jobs, we couldn’t actually use this data directly. While the existing conversations were critical in helping us understand our user types, conversational failure modes, and strength areas, we had no way of using those exact conversations to re-run against different models or different prompts or different configuration options. Consider the following hypothetical chat transcript:

If we wanted to use this data to re-run the same conversation with a new model, we could consider the user’s messages as the hard-coded inputs for recreating the conversation. Let’s say, as a hypothetical, that the original transcript was generated using OpenAI’s GPT-5.1, and to see how Anthropic’s Haiku 4 would do in the same situation, we used the user’s exact same inputs to attempt to simulate the conversation.
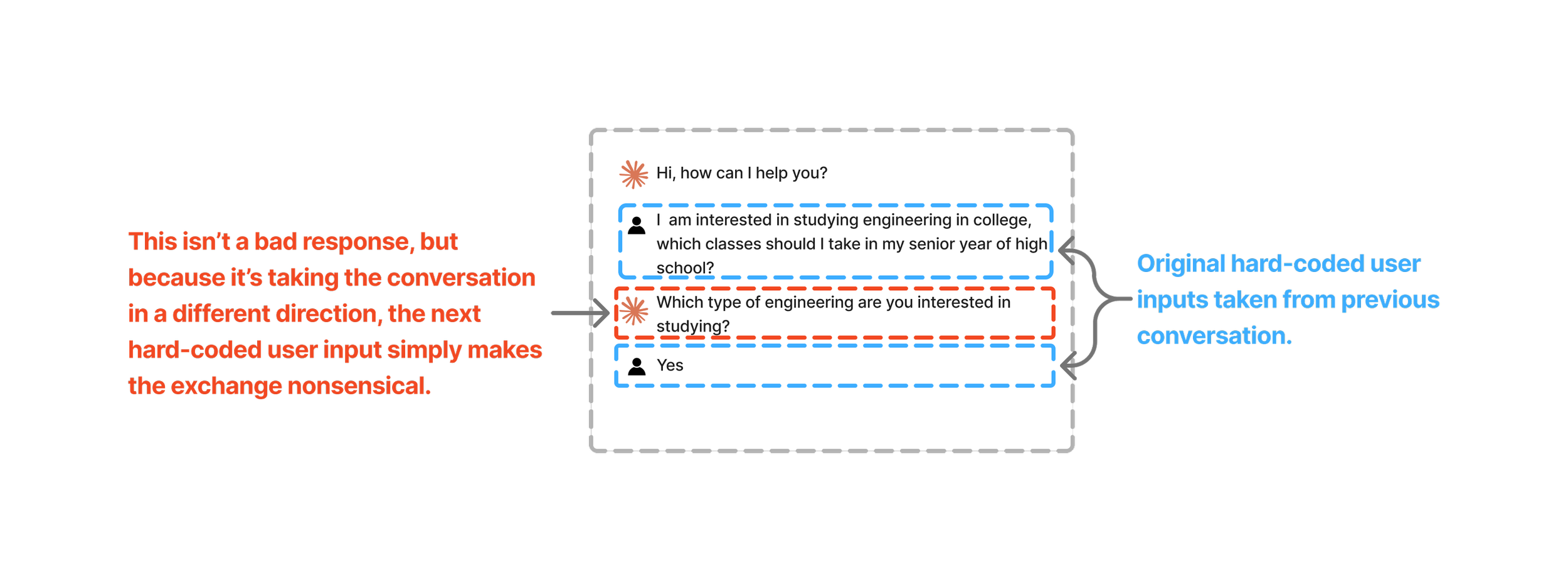
While this example is a bit contrived, it hopefully illustrates the trouble with trying to use historical conversational data as a direct input for testing new models, configurations, or prompts in your application. In this case, the non-deterministic nature of LLMs forces us to consider more creative approaches for generating representative conversations for testing.
Instead of feeding user inputs directly into our systems with new configurations, we decided to leverage our historical conversation data indirectly. Our solution was to create representative user personas that attempted to capture the feelings, attitudes, and contexts present across our distribution of users.
Our work developing these personas consisted of reviewing conversation transcripts across users with a spectrum of experiences within our application; those with varying activity levels, differing survey responses, countries of origin, etc. Each representative user persona we created then served as an input for an LLM prompted to simulate how a user with that particular profile would respond to Coach. In essence, we pivoted to creating synthetic data that was rooted in the historical behavior of our users. By running each of these synthetic users across the combination of configuration options we wanted to test, we were able to generate a new set of conversations that we could then feed into our ensemble-based evaluation system.
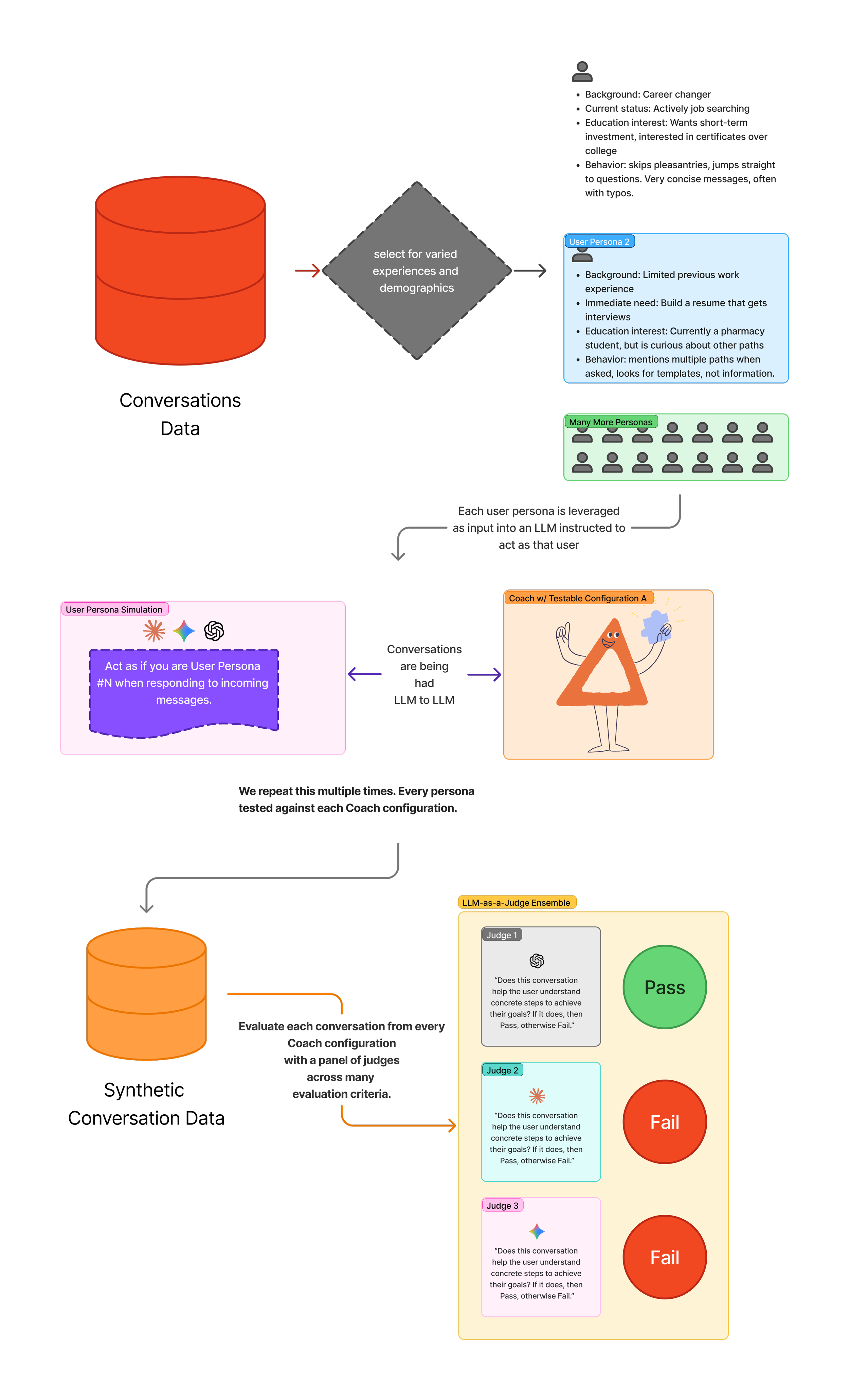
Our end-to-end evaluation system for Coach for validating quality of outputs during experimentation.
Supplementing with application-specific deterministic tests
Everything previously discussed outlines how we test the quality of conversational content. Which is admittedly a very significant portion of what we care about. However, there are smaller application-specific considerations for Coach that don’t fall within the scope of “conversation quality” and, as such, are not handled well by the LLM-as-a-Judge approach. In order to create a robust evaluation system that accurately measured our end-to-end functionality, we needed to take other factors into consideration. In this section, we’ll walk through two specific such considerations. While these considerations are specific to how we’ve built Coach, we’re exploring them here to share examples of how LLM-as-a-Judge often isn’t enough and should be supplemented with identified application-specific failure modes.
Citation URL hallucination
For most conversations that Coach engages in, we include instructions that tell it to include citation links to relevant sources wherever possible. In most cases, this is done with tool-based retrieval for specific URLs. However, in some testing instances, we’ve seen models fail to call a tool and return a legitimate URL that contains relevant data. In other cases, we’ve seen models fail to call a tool and then hallucinate a realistic-looking URL that actually leads to nowhere. As a simple, deterministic test, we created a script that uses regular expressions to detect links in chat responses and then pings them to validate that they are at minimum real URLs that return 2xx status codes. Simple tests like these are cheap to write, deterministic, and can help detect how different prompts, models, or configurations might reintroduce known failure modes into your system.
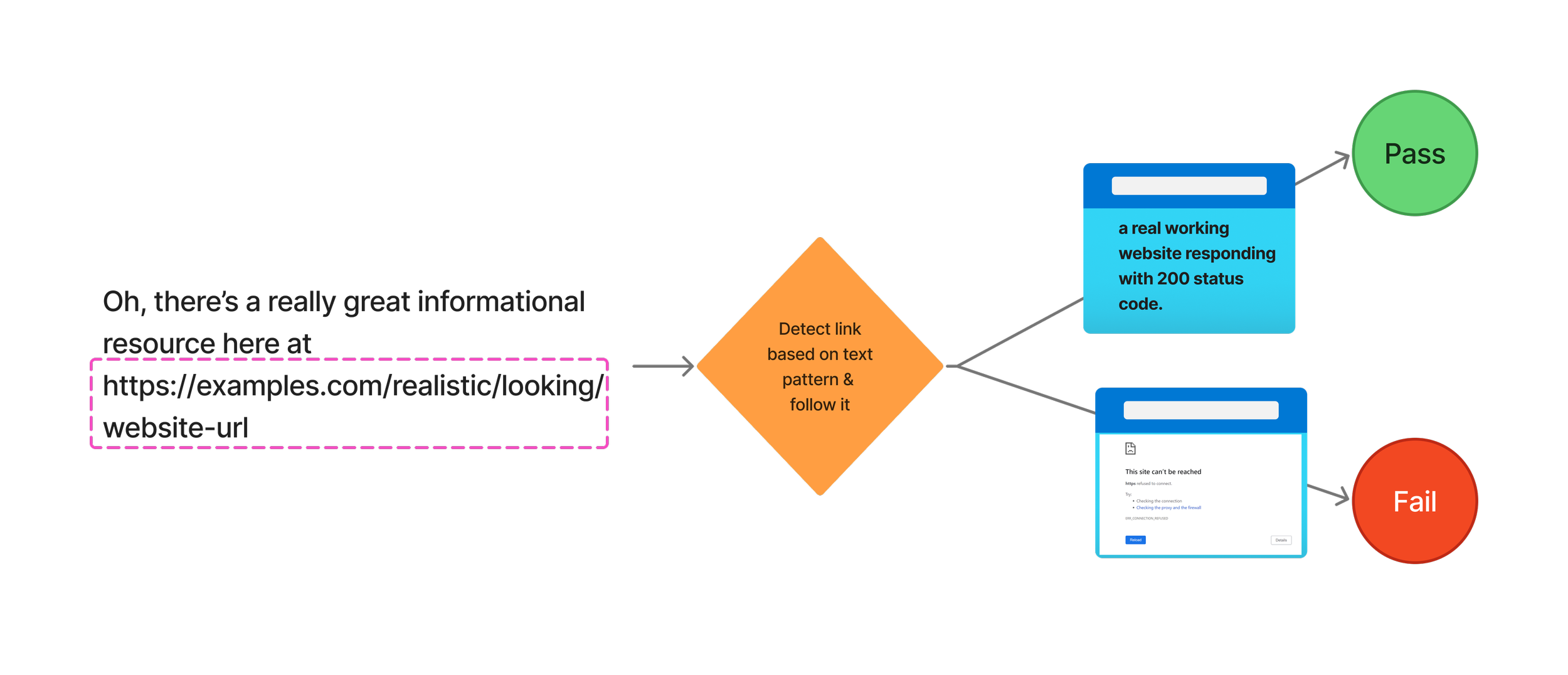
Whenever Coach produces links, they always look realistic. We use a test like this to make sure that they lead to real and active websites. Early on in development, URLs were one of the most common places that we found hallucinations occuring.
Text schema-based rendering
Another application-specific failure mode we built tests for is our in-chat interactive rendering. For certain activities, Coach often creates interactive elements that users can click on directly to trigger an action or see more detailed information. One example would be in our job exploration activity; we have integrations with a number of job feeds that allow us to surface relevant job postings mid-conversation (it's really cool). We do this by prompting Coach to represent job postings with a very specific text format (sometimes referred to as a schema). When our front-end sees this very specific combination of text, it knows to show a clickable job posting card instead of the text itself. But, if Coach gets the text format incorrect, then jobs simply don’t show up, or worse, the ill-formatted text schema will show up directly in the chat, which would be an unpleasant and confusing experience for our users. So, to prevent new models or other configuration changes from introducing these types of bugs, we created a regular expression based test as part of our suite that validates that the text format matches the expected schema.
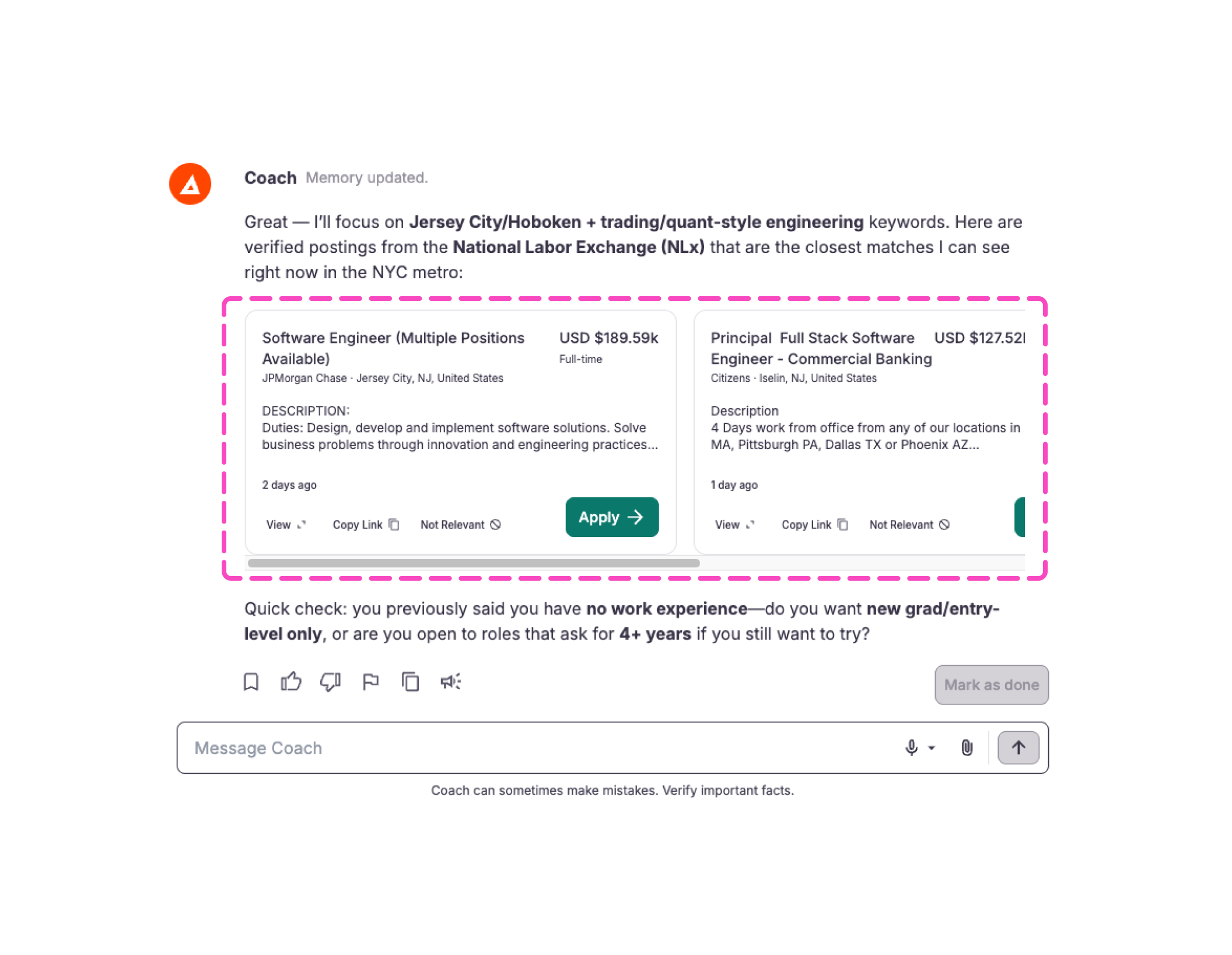
The job cards highlighted in pink are rendered based on a very specific text schema produced directly by an LLM. So whenever we change models or prompts, we run tests that validate that Coach still consistently produces text that complies with our schema.
Validating with human annotators & beyond
As a last step, we want to make sure that all the fun techniques we’ve been dreaming up and working on actually approximate what we set out to mimic– human judgment. To check our end results, we took a random sample of generated conversations and judged them on the same criteria as our LLM counterparts. We then compared our human-generated evaluation scores with those output by our ensemble of judges. In the event that we had disagreement in the samples, we would take a closer look at the conversation and figure out if there were additional adjustments to the prompt or criteria that needed to be made.
Final output
When it was all said and done, we ended up with something like this. While these numbers and criteria are not exactly what we used internally, the idea is the same. For all the synthetic conversations generated from the derived user personas, figure out how well each configuration (in this case just the model choice in the first column) performs across the dimensions that matter most for your use case!
| LLM Model | Latency | Warm Tone | Fairness & Bias | Actionable Advice Given | Link Generation Success Rate | How Reliably is Application Specific Interactivity Leveraged | Cost Reduction (%) | Weighted Overall Quality | Quality Retained (% of Baseline Model) |
|---|---|---|---|---|---|---|---|---|---|
| Model 1 | 2.45 | 85.60% | 80.00% | 82.0% | 100% | 100% | 84.8% | 35.68 | 89.7% |
| Model 2 | 4.47 | 85.40% | 64.00% | 88.0% | 99% | 100% | -10.6% | 31.27 | 78.7% |
| Model 3 | 3.77 | 84.00% | 44.00% | 89.0% | 100% | 100% | 91.3% | 9.63 | 24.2% |
| Model 4 | 1.10 | 81.80% | 88.00% | 77.0% | 98% | 100% | 88.4% | 28.58 | 71.9% |
| Model 5 | 4.38 | 81.80% | 77.00% | 68.0% | 97% | 100% | 0.0% | 39.75 | 100.0% |
| Model 6 | 1.70 | 80.60% | 91.00% | 91.0% | 89% | 0% | 96.1% | 27.05 | 68.1% |
This is a simplified version of a "scorecard" output that would be produced after completing all the steps outlined above. Each column represents the aggregated score achieved on a given test. Each row represents a different LLM model. However, you could also imagine designing a different experiment in which each row represents varying something else, like a differently worded instructional prompt, for instance.
Future optimizations
Throughout this article, we've outlined the current state of affairs for our offline on-demand evaluations systems here at CareerVillage. In the not too distant future we hope to leverage some additional steps to bring down the cost of evaluations and integrate the workflows we've described here with our online evaluations that run continuously on samples of real user conversations. We think that there are a number of opportunities to use fine-tuning as a method of knowledge distillation5 to improve the reliability of evaluative models while also reducing the cost.
We believe that the approach outlined in this article represents a significant step forward in our ability to fulfill our goal of building the most trusted AI-powered career coach. Our system gives us the ability to explore the vast array of configuration and model options without fear of quality loss; allowing us to experiment as the technical landscape continues to evolve rapidly.
- We are referring to randomness as the product of LLM sampling techniques driven by parameters like temperature and top-p or top-k. Back to text
- BLEU (Papineni et al., 2002), a precision-based metric introduced by IBM researchers in the early 2000s, was subsequently expanded on with the release of ROUGE (Lin, 2004) by researchers at the University of Southern California. ROUGE emphasized recall and became popular for evaluating summarization task outputs. METEOR (Banerjee and Lavie, 2005), published by researchers at Carnegie Mellon University, built on BLEU by being more forgiving of morphological variations (like run vs ran vs running), synonyms (like shoe vs sneaker), and word order. Although METEOR was shown to correlate more closely with human judgment, it was slower and more complex to use, which meant it has been less widely adopted than BLEU. Back to text
- In 2023, Zheng et al. identified a “self-enhancement” bias in LLM-as-a-Judge setups, where a model tends to score its own outputs more favorably. Subsequent work, such as Narcissistic Evaluators and Self-Preference Bias in LLM-as-a-Judge, expanded on this finding, showing that this effect generalizes to outputs that align with a judge model’s style or training distribution, formalizing the idea of self or family-preference bias. Back to text
- Researchers at the New York University Alignment Research Group with support from Anthropic and Cohere showed that a model’s stated explanation for why it produced a given output is often highly variable and operates more like a post-hoc justification for an answer as opposed to a faithful reproduction of the internal reasoning (Turpin et al., 2023). This finding added important nuance and complication to the 2022 paper released by the Google Brain Research Team that showed how prompting for CoT reasoning could lead to higher quality outputs from LLMs (Wei et al., 2022). Back to text
- We use knowledge distillation to refer to the practice of training a smaller “student” model to imitate the outputs of a larger “teacher” model. In LLM settings this can be done by producing synthetic target data from a more expensive slower model and then using those as training labels to fine-tune a cheaper faster model. When it works well, distillation produces a more computationally efficient model that retains much of the teacher’s performance on the tasks of interest. This idea has origins in early work on model compression via teacher-labeled pseudo-data (Bucilă et al., 2006) and was later popularized as knowledge distillation (Hinton et al., 2015), including extensions to sequence/text generation (Kim & Rush, 2016). Back to text